안정적인 서비스 만들기
안정적인 서비스를 만들기 위해서 가장 필요한 것은 성능 개선이다.
성능 개선이 되면 서버와 클라이언트의 리소스가 크게 절약될 수 있고,
사용자는 서비스 만족도가 올라가므로 모든 서비스는 성능 개선을 목표로 하고 있다.
이번 미션에서는 안정적인 서비스를 만들기 위해 성능 개선을 어떤 부분에서 접근할 수 있는 지,
특히 Back-end 에서 개선할 수 있는 점에 집중해서 살펴보았다.
리버스 프록시 개선(HTTP 개선)
- http 1.1의 문제와 http 2.0 의 해결방법
- reverse proxy 성능개선
- gzip 압축을 통한 content-encoding 최적화
HTTP Cache 활용
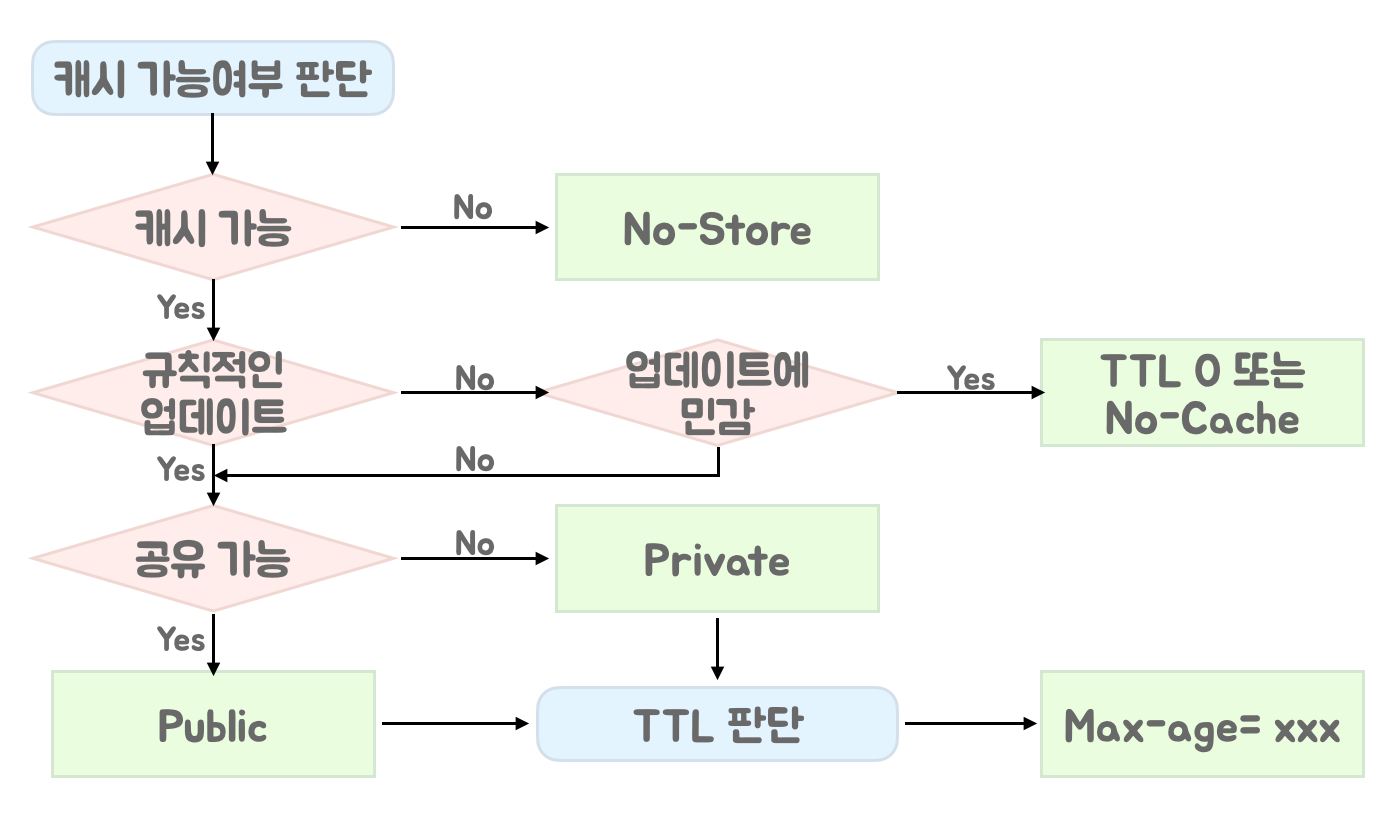
- HTTP 캐싱을 활용한 서버 리소스 최적화
- Cache-Control
- no-cache : 매 요청마다 중간에 있는 캐시 서버들은 ETag(checksum 비슷한 값)를 통해 자원의 유효성을 확인
- max-age = 0 과 같다
- no-store : 캐시하면 안되는 데이터에 대한 처리(개인정보, 민감정보 등등)
- public : 중간 단계를 포함한 모든 캐시 서버에 캐시가 가능
- private : 요청한 사용자만 캐시 할 수 있음 (
- 주의) 개인정보를 보호한다는 의미는 아님
- no-cache : 매 요청마다 중간에 있는 캐시 서버들은 ETag(checksum 비슷한 값)를 통해 자원의 유효성을 확인
MySQL 최적화 대상
- Client : DB를 사용하는 클라이언트 (애플리케이션 서버)
- 복수 건의 레코드를 한번의 호출로 집합 처리하거나, 두 개 이상의 쿼리를 한 쿼리로 통합처리
- JDBC Statement는 쿼리 문장 분석, 컴파일, 실행단계를 캐싱한다.
PreparedStatement 는 처음 한 번만 세 단계를 거친 후 캐시에 담아서 재사용한다. - DB Connection Pool 사용으로 Connection 과 연관된 객체 생성 대기시간을 줄이고, 네트워크 부담도 줄일 수 있다.
- Fetchsize 를 조정하거나 Paging 을 활용한다.
- Database engine
- 파일시스템에 저장된 데이터가 조회되면, 해당 데이터를 메모리에 저장해
이후 동일 데이터 조회 시 파일 시스템의 물리적인 입출력을 미연에 방지 - 서버 파라미터를 튜닝한다
- 파일시스템에 저장된 데이터가 조회되면, 해당 데이터를 메모리에 저장해
- Filesystem
- SSD를 사용
- SQL를 최적화하여 필요이상의 데이터 블록을 읽는 것을 방지,
즉 SQL 튜닝이란 FileSystem 에서 읽는 블록 수를 줄여 주는 것을 의미
사실상, 프레임워크나 Public Cloud 를 사용하고 있다면,
물리적 자원, 애플리케이션 서버에서는 상당 부분 최적화 되어 있다.
빠른 쿼리를 위한 7가지 체크리스트
를 참고해도 좋을 듯..
실행계획과 인덱스
Index를 사용하는 경우, Random I/O 횟수를 줄이는 것이 관건
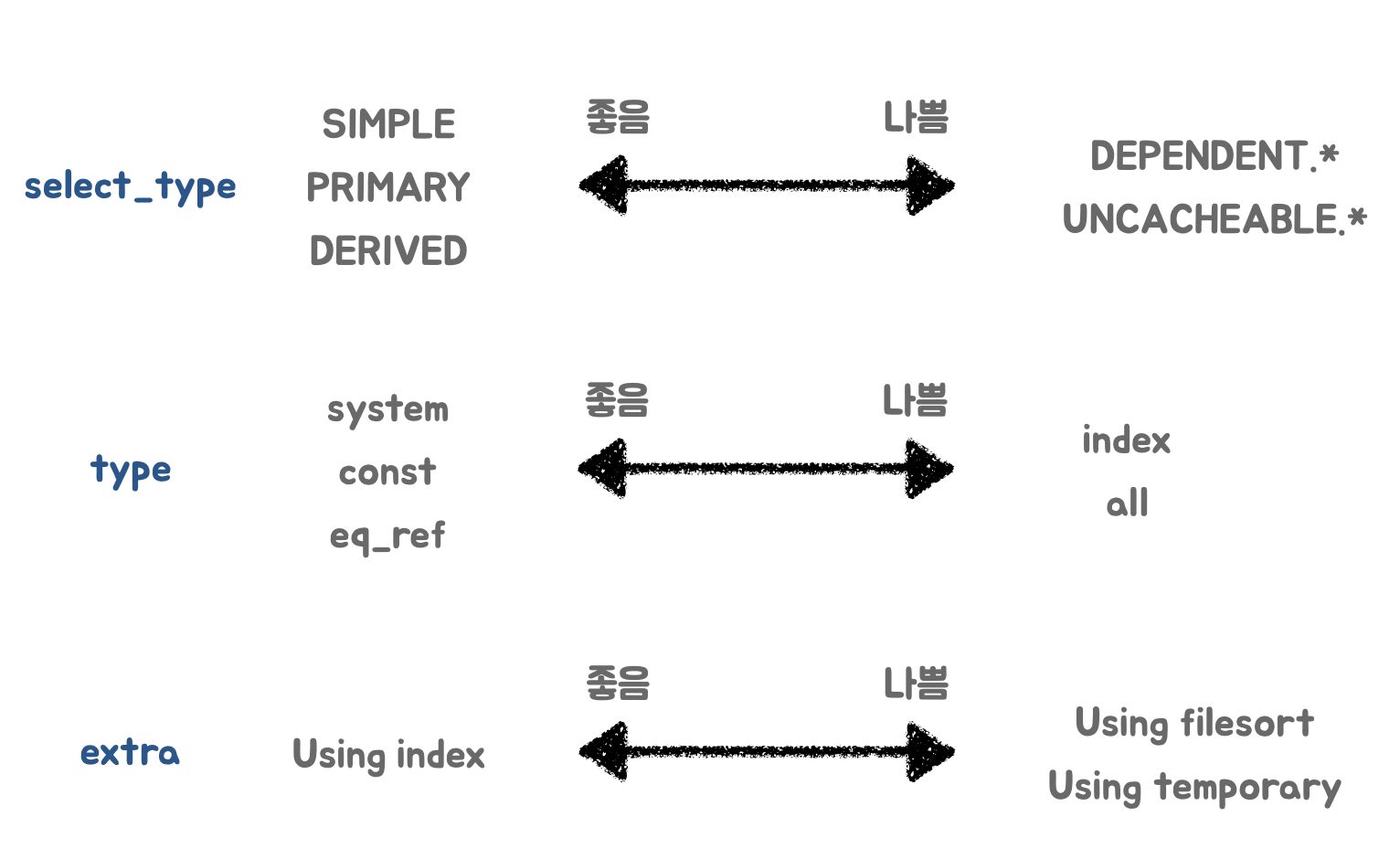
- 실행계획 확인
- Full Scan : FileSystem에 저장되어 있는 모든 블럭을 탐색하는 것 –> 최악
- 인덱스를 타도록 조정해야 한다.
- 조건절 컬럼, 조인/서브쿼리 구조, 정렬 등을 확인
- Index Range Scan 을 위해선 인덱스 선두 컬럼이 조건절에 있어야 한다.
- 테이블 액세스 최소화
- 단일 인덱스 vs 복합 인덱스
- 인덱스 현황을 파악
- 인덱스 설정에 정답은 없다. 조회하는 쿼리에 따라 가장 적합한 인덱스를 선택하는 것이 정답
쿼리 튜닝하기
- 인덱스
- 인덱스 컬럼을 가공하지 말 것
- 리프블록의 스캔 시작점부터 중간에 멈출 수 있다.
- 인덱스 순서를 고려
- 인덱스 순서에 따라 Order by, group by 를 위한 sort 연산을 생략할 수 있음
- 인덱스를 제대로 사용하는 지 확인
- Covered Index : 인덱스 스캔 과정에서 얻은 정보만으로 처리할 수 있어 테이블 액세스가 발생하지 않는 쿼리
- 복합 인덱스 시 범위 검색 컬럼을 뒤에 둬야 한다
- 인덱스 구성 확인
1
2
3
4
5
6
7
8
9
10
11
12
13
14## 테이블 / 인덱스 크기 확인
SELECT
table_name,
table_rows,
round(data_length/(1024*1024),2) as 'DATA_SIZE(MB)',
round(index_length/(1024*1024),2) as 'INDEX_SIZE(MB)'
FROM information_schema.TABLES
where table_schema = 'subway';
## 미사용 인덱스 확인
SELECT * FROM sys.schema_unused_indexes;
## 중복 인덱스 확인
SELECT * FROM sys.schema_redundant_indexes;
- 인덱스 컬럼을 가공하지 말 것
- 조인
- 조인 연결 Key 들은 Join 대상 테이블 모두에서 인덱스를 가지고 있을 것
- 데이터가 적은 테이블을 랜덤 액세스 해야한다.
- 모수 테이블 크기를 줄인다
- 서브쿼리보단 조인문을 활용한다
회고
느낀점
배민, 네이버, 카카오 등의 굴지 대기업들이 수 많은 사용자의 요청을 어떻게 처리할 수 있는 지
엿볼 수 있는 좋은 경험이었다.
이번 미션에서 느낀점을 한줄로 표현하자면,
안정적인 서비스를 만든다는 것은 ‘최소의 리소스로 최상의 퍼포먼스를 내는 것’ 이라는 생각이 들었다.
대략 이런 생각을 하기까지 머리속에 맴돌던 질문들을 정리해보자면 아래와 같다.
Q) 최소의 리소스를 사용하려면 어떻게 해야할까?
- 리소스를 사용하지 않게 만드는 것이다.(서버의)
Q) 그렇다면, 리소스를 사용하지 않게 만드려면 어떻게 해야할까?
- 캐시를 사용한다.
Q) 캐시를 사용했을 때 부작용은?
- 캐시 데이터와 서버 데이터의 비동기
Q) 비동기 문제를 어떻게 해결할 것인가?
- 클라이언트가 요청할 때 동기화 여부 확인
- 서버가 업데이트 되는 경우 일괄 캐시 서버 / 클라이언트에게 알림
두 가지 방법 중 단연 전자의 경우가 훨씬 효율적이기 때문에 채택
Q) 리소스를 아예 사용하지 않을 수는 없을 텐데 그때는 어떻게?
- 서버 차원에서 리소스 사용량을 최소화 하도록 애플리케이션을 개선한다.
- 비즈니스 로직 개선
- 네트워크 개선
- 쿼리 튜닝
이렇게 원인을 찾아보며 미션을 진행하다 보니,
개인적으로 앞으로 학습할 주제에 대해 생각해 볼 수 있었다.
그리고 성능 전 후 비교한 수치가 크게 차이날 때,
엄청난 성취감이 생겼다.
마지막으로 머리속으로 알고있는 것과 실제 해본것의 차이를 확실히 알게되었다.
이제까지 어떤 기술에 대한 개념을 학습할 때, 각종 docs 나 포스팅을 찾아보며
개념만 숙지하고 넘어가곤 했다.
하지만, 실제로 환경을 구성하고 그 차이를 눈으로 비교한 것 과는 이해도가 확연하게 차이나는 것을 몸소 체험했다.
앞으로 학습하는 과정에서 개념 숙지 후 반드시 실습까지 해봐야 겠다.